画像検索、動画説明から詩作、文章の続きを書くことまで、さらに音声認識、2言語翻訳。バーチャルヒューマンの「小初」がこのほど、世界人工知能大会2021に登場した。画像、文書、音声という3モードのスマートな変換と生成を披露した。新華社が伝えた。
小初がこのような能力を持つのは、「紫東太初」と呼ばれるクロスモダリティ汎用型人工知能(AI)プラットフォームによるものだ。中国科学院自動化研究所が開発した同プラットフォームは、国産化基礎ソフト・ハードウェアを採用し、一つのビッグモデルだけでAIの視覚、テキスト、音声の複数シーンにおける理解力を「トレーニング」できる。
中国科学院自動化研究所の徐波所長は、「『ビッグデータ+ビッグモデル・マルチモダリティ』が現在の単一モデルが単一任務に対応するAI開発パラダイムを変える。マルチモダリティビッグモデルが異なる分野の共通プラットフォーム技術になり、汎用型AIに向かう重要な道だ」と説明した。
徐氏は「紫東太初は画像、文書、音声という3つの様式の統一表現を実現。画像から音声を生成し、音声から画像を生成。AIの動画音声吹込、音声による放送、タイトルのダイジェスト、ポスター創作などより多様なシーンにおける応用を切り開く」と述べた。
中国科学院自動化研究所は中国語プレ訓練モデル、音声プレ訓練モデル、視覚プレ訓練モデルを構築したうえ、クロスモダリティ語義関連により、3様式プレ訓練ビッグモデルを構築した。(編集YF)
「人民網日本語版」2021年7月15日
 車体後部に信号灯を表示するスマートバスが登場 湖南省長沙
車体後部に信号灯を表示するスマートバスが登場 湖南省長沙
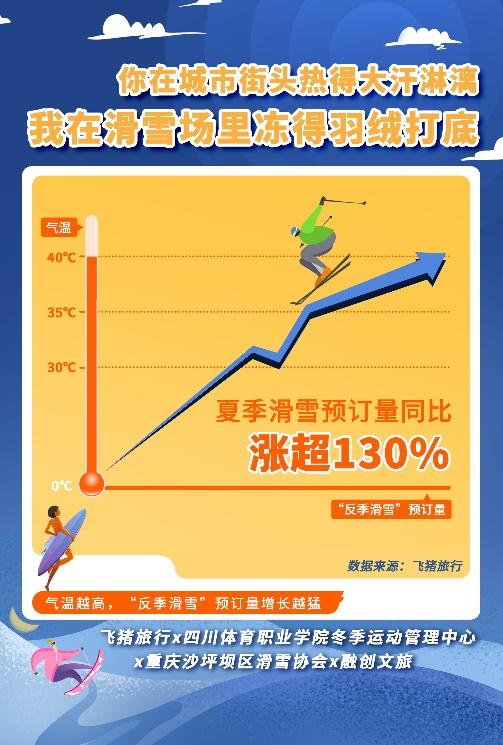 南方都市で楽しむ夏スキー 予約数が激増し、全国トップは重慶
南方都市で楽しむ夏スキー 予約数が激増し、全国トップは重慶
 さあ、早起きしよう!早起きを推進する大学サークルのユニーク…
さあ、早起きしよう!早起きを推進する大学サークルのユニーク…
 10キロの重りを身につけ水中で太極拳を舞う1990年代生ま…
10キロの重りを身につけ水中で太極拳を舞う1990年代生ま…
 新型コロナ臨時医療施設入院中に医学の道を決めた女性、医学系…
新型コロナ臨時医療施設入院中に医学の道を決めた女性、医学系…
 紙っぺら1枚の「最もお粗末な合格通知書」が話題に
紙っぺら1枚の「最もお粗末な合格通知書」が話題に











